我们先通过一段代码来看看js的执行过程:
showName()
console.log(myname)
var myname = '极客时间'
function showName() {
console.log('函数 showName 被执行');
}了解javascript语言的都知道,js是按顺序执行的。按照这个逻辑来理解这段代码的话:
- 第二行由于
showName函数未定义,执行应该也会报错。 - 第一行由于
myname变量未定义,执行应该会报错。
然而实际结果却是:

第一行的函数正确执行了,而第二行中的变量输出却为undefined。通过上面的结果我们可以得知,js中的函数和变量可以在定义之前使用。
此时我们删除第三行中的name变量的定义,再次执行,js引擎将报错:
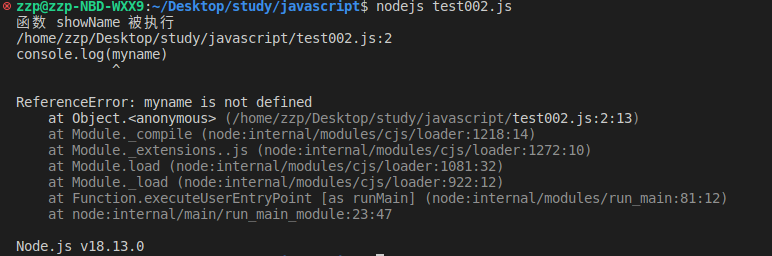
通过以上两段代码我们能得出三个结论:
- 在js代码执行过程中,如果使用未声明的变量,将直接导致程序异常报错。
- 在一个变量定义之前使用该变量,变量输出的结果为
undefined。 - 在一个函数定义之前使用该函数,函数能够正常执行。
为什么会出现这些令人不解的结论?这是由于javascript变量提升的机制决定的。
执行上下文
什么是变量提升?所谓的变量提升,是指在 JavaScript 代码执行过程中,JavaScript 引擎把变量的声明部分和函数的声明部分提升到代码开头的“行为”。变量被提升后,会给变量设置默认值,这个默认值就是我们熟悉的 undefined。
为了模拟变量提升的效果,我们假定上段代码在编译执行过程中做了以下调整,方便理解:
// 定义过的变量myname被提升,并赋予初始值undefined
var myname = undefined
// 定义过的函数get_height被提升
function showName(){
console.log("showName 被调用")
}
showName()
console.log(myname)
// 去掉myname变量var声明,保留赋值语句
myname = '极客时间'从变量提升字面意思上理解,就是变量声明和函数声明在物理层移动到最前面。但是实际上变量声明和函数声明在代理里的位置是不会改变的,而是在编译阶段被js引擎放入内存中。是的,js代码会先编译再执行。

编译阶段
我们通过一张图来分析编译阶段,js在内存中的表现:
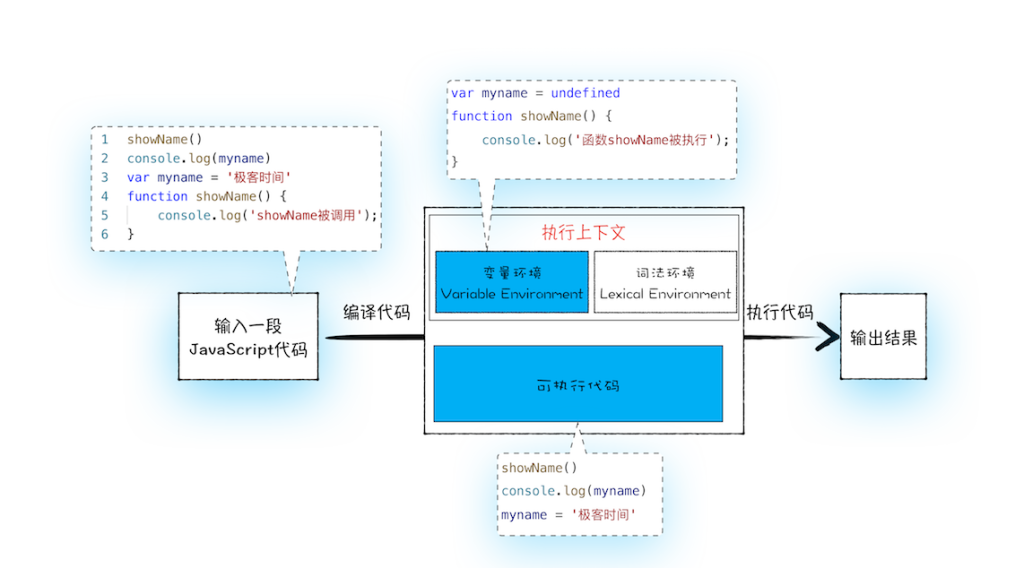
从上图可以看出,当一段代码经过编译后,在内存区域中会生成两部分:执行上下文和可执行代码。
执行上下文是 JavaScript 执行一段代码时的运行环境,比如调用一个函数,就会进入这个函数的执行上下文,确定该函数在执行期间用到的this、变量、对象等。而执行上下中存在一个变量环境对象,该对象中保存了变量提升的内容。该对象可以简化理解成以下的形式:
"variableEnvironment":{
"myname":undefined,
"showName":func()的reference
}变量环境对象是如何生成的呢?我们通过最开头的原始代码来分析:
- 第一二行代码不是声明操作,js引擎不做处理
- 第三行代码是变量声明,js引擎在变量环境对象中添加一个
myname属性,并赋值undefined,如上述代码。 - 第四到六行是一个函数声明,js引擎将函数存放到HEAP堆中,并在变量环境对象中添加一个showName属性,赋值上HEAP堆函数所在的引用。
- js引擎会把声明以外的代码编译成字节码。
执行阶段
执行阶段就比较简单了,逐行执行。执行第一行函数的时候就去执行上下文中的变量环境对象寻找是否存在同名属性,发现变量环境对象中存在堆函数的引用,遍找到堆函数执行相应的函数。执行到第二行是输出一个变量,继续去执行上下文中的变量环境对象中寻找是否存在该属性变量,发现存在且值为undefined。第三行是变量赋值操作,如果当前执行上下文变量环境对象中存在该变量,便更改当前对象的属性值。
同名变量或函数的可执行上下文
先来看看下面的函数输出:
showName()
function showName() {
console.log(1)
}
function showName() {
console.log(3)
}
var showName = function() {
console.log(2)
}上面的输出为3。为什么会是这个结果,关于同名变量和函数的两点处理原则:
- 如果是同名的函数,JavaScript编译阶段会选择最后声明的那个
- 如果变量和函数同名,那么在编译阶段,变量的声明会被忽略
调用栈
前面说了执行上下文是在一段js编译代码时产生的运行环境,假设一个页面上万行代码也算一段代码吗?以下两种情况下会产生相应的执行上下文。
- 全局代码开始编译执行的时候,产生的是全局执行上下文。在整个页面生命周期中,全局执行上下文只有一个。
- 函数在调用执行的时候,会产生函数执行上下文。一般情况,函数在执行完会销毁该执行上下文。
也就是说在执行js代码时,会产生多个执行上下文。而多个执行上下文的管理就是通过栈的形式管理,在执行上下文创建好以后,js引擎就会将该执行上下文压入栈中。我们将这种管理执行上下文的栈叫做执行上下文栈,也叫调用栈。
接下来通过一段代码来分析调入栈的变化情况:
var a = 2
function add(b,c){
return b+c
}
function addAll(b,c){
var d = 10
result = add(b,c)
return a+result+d
}
addAll(3,6)第一步,整段代码在编译过程中会产生全局执行上下文。js引擎将全局执行上下文压入栈底。经过变量提升后,此时全局执行上下文中的变量环境对象如以下形式:
"variableEnvironment":{
"a":undefined,
"add":func()的reference,
"addAll":func()的reference,
}第二步,整段代码编译完后,就进入执行过程。当执行到addAll函数的时候,此时js引擎会编译该函数,并产生关于addAll的函数执行上下文,将其压入栈中。此时变量环境中除了变量环境对象还存在参数列表,如下:
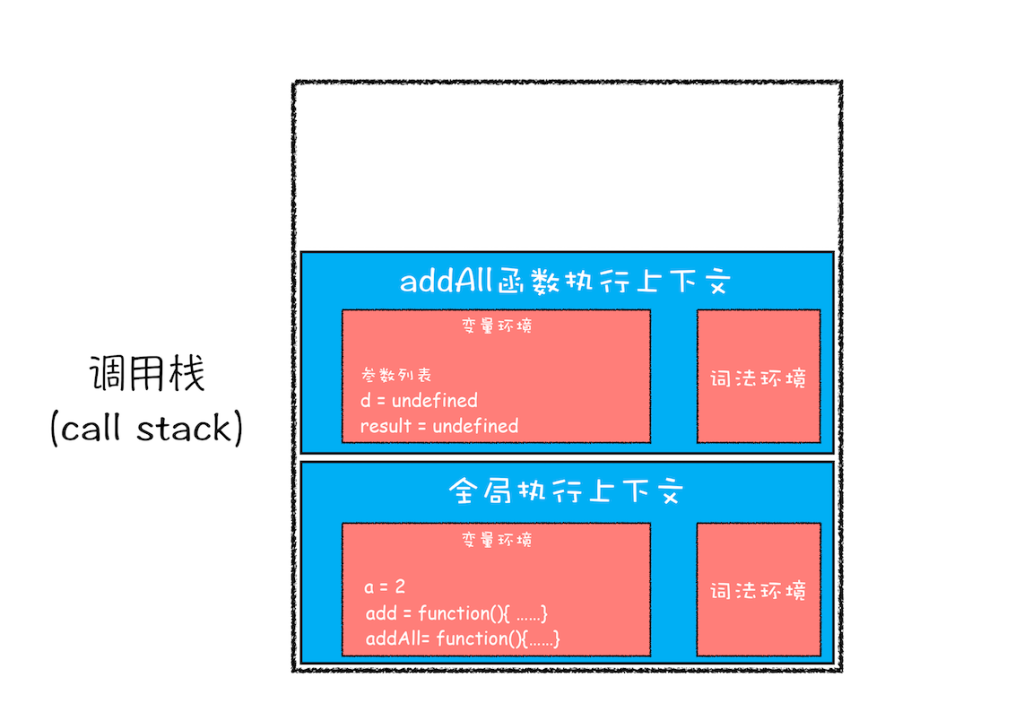
"parameterList":{
"b":3,
"c":6
}
"variableEnvironment":{
"d":undefined,
"result":undefined
}第三步,当addAll函数中执行到add函数的时候,js引擎会编译产生新的all函数上下执行文,并将其压入栈中。此时的调用栈和变量环境如下:
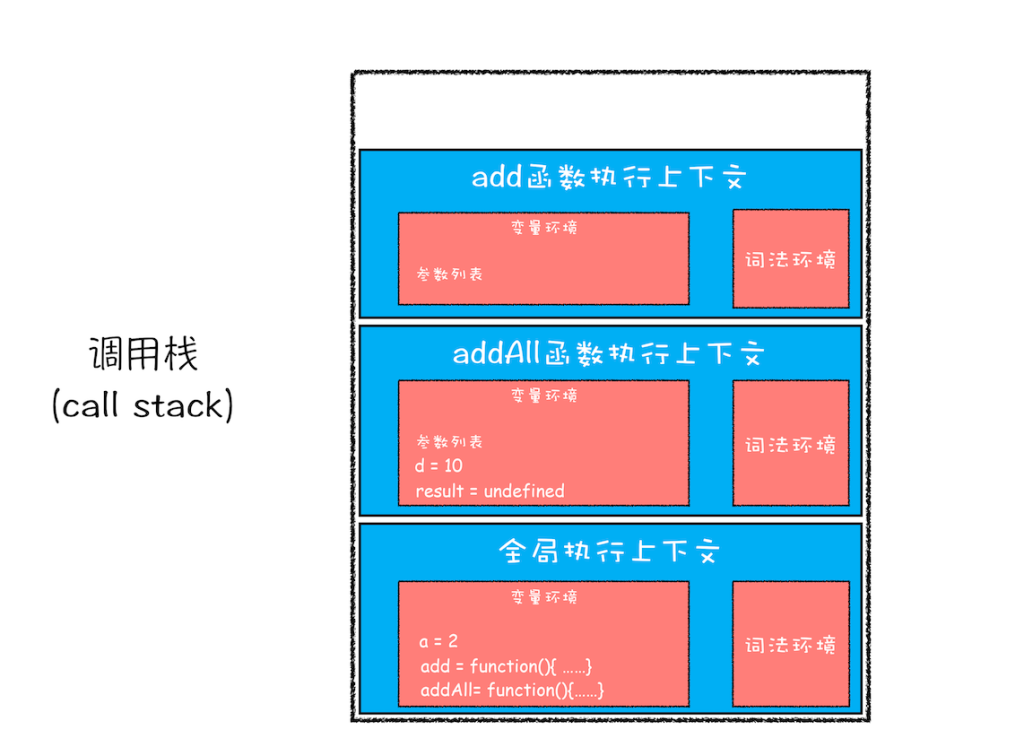
"parameterList":{
"b":3,
"c":6
}第四步,当add函数执行后返回后,js引擎会将该函数执行上下文从调用栈中弹出销毁。重复如此,直到全局可执行代码执行完成。
至此,整个js代码的流程执行结束。调用栈就是js引擎追踪函数执行的机制,当一个或多个函数执行时,就能通过调用栈跟踪到当前执行的函数以及函数调用之间的关系。
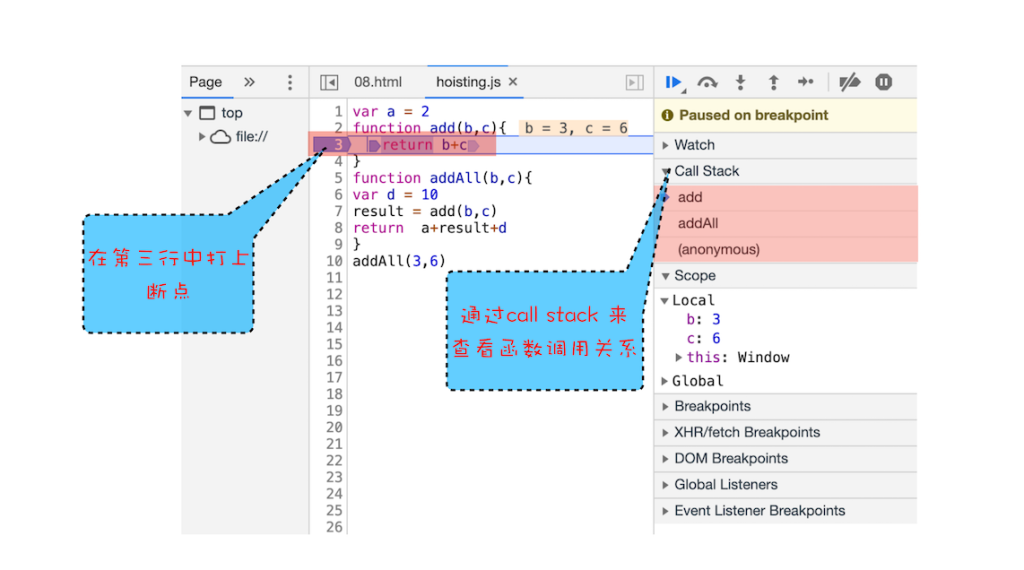
Chromium系浏览器查看调用栈信息
打开“开发者工具”,点击“Source”标签,选择 JavaScript 代码的页面,然后在第 3 行all函数加上断点,并刷新页面。你可以看到执行到 add 函数时,执行流程就暂停了,这时可以通过右边“call stack”来查看当前的调用栈的情况,如图:
参考学习链接
https://time.geekbang.org/column/intro/100033601